the following changes have been pushed to bugzilla.mozilla.org:
- [1439693] Update bug form.mdn for developer.mozilla.org product name
- [1440107] Allow ‘self’ frames in bug modal again (fix socorro lens)
discuss these changes on mozilla.tools.bmo.
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
Among a bunch of other things that are going on, we’re migrating bugzilla.mozilla.org to a new home in AWS.
So the team (bobm and ckolos) have been very dedicated to validating the new stuff is as good, and hopefully better than the old stuff. To this end they’ve been working with another engineer (rpapa) to do load testing. Some of the load testing results have been a bit unusual, perhaps even impossible.
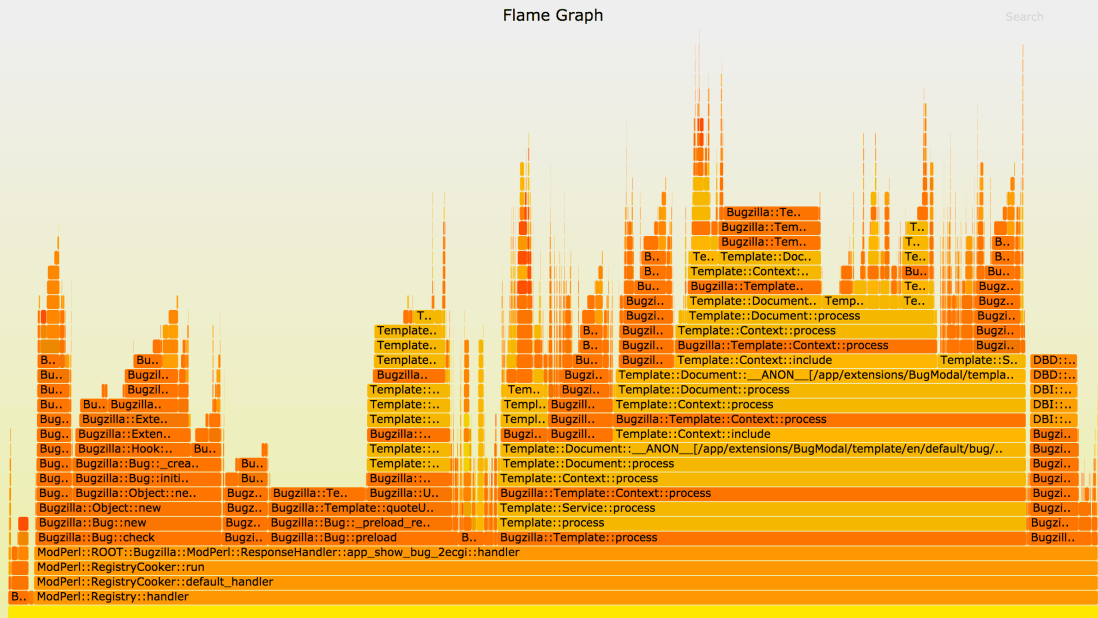
But that’s okay, because I’ve recently made it very easy to profile the code using Devel::NYTProf.
Looking at preliminary profile data, it seems that perhaps the overhead of connecting to mysql may be higher in the new environment.
It could also be something else — more analysis is needed.
I’m sure this must be a thing, but to be honest I haven’t ever read about someone using a profiler in this way, so perhaps is deserves a mention.

I’m still hammering out what features I want to see land in BMO this year but one thing I’ve come to realize is that often the way forward on an old code base is through careful deprecation.
Adding new features, or even fixing existing bugs is often blocked by the immense weight of past decisions.
Recently we deprecated support for IE 11.
This was magic: We can use more modern javascript features. async/await, arrow functions, and so on make the frontend code much nicer to work with. It puts us on a good footing to remove our use of legacy JS frameworks and (I believe) makes contributions more attractive.
This is not to say we will enthusiastically deprecate everything that holds us back, but a measured approach is called for here.
I’m going to list the things that I intend to deprecate in the first half of 2018. This isn’t a roadmap for 2018 but these deprecations and changes will feed into that.
Right now we spend a lot of time rendering comments.
It would be nice to cache them — but they’re not cache-able in general because they contain user-specific data. That is, if you can see a security bug you’ll be able to see its description in the mouse-over hover of a bug.
After looking at several options for this, I realized it would be better to add the tool-tips client side.
While not a silver bullet, this also paves the way for adopting markdown (something I’m actively working on).
Benefit: Faster page loads, especially on popular bugs with more than a few dozen comments.
So if you use Firefox, you get a much better experience using buglist.cgi. You see the chomping dinosaur while your search results are collected. Unfortunately, this doesn’t work in any other browser, and it isn’t standardized. As a result, we have to be very careful with our load balancers and so on.
Making this fetch() call is pretty easy, but supporting both as an in-page fetch() and an HTTP push is quite hard. So when this switches to a fetch() the HTTP push is going away.
This is almost not a deprecation because the functionality will be mostly the same.
Benefit: Firefox users will get a better UX when request times out, and everyone else will benefit too.
Right now 90% of page views hit a page that uses CSP. But many people
continue to use the legacy HTML view, which cannot do CSP because of the
InlineHistory Bugzilla extension. The legacy bug page is deprecated already
— it does not receive updates and we don’t care much about UX regressions
on it.
Short of just turning it off, I’m going to enable CSP for it. This means
inline history won’t work.
At some point, we’re just going to turn it off, and this is a step towards that.
Benefit: Security, less bad javascript to maintain.
Already javascript: links in the URL field do not work on the main bug view
page. Now all bug URL links that are marked “unsafe” will appear as
clipboard-copyable text areas.
Benefit: Usability, you’ll be able to more easily use test-cases that are javascript: links.
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
So for various reasons — including “I want bugzilla.mozilla.org to support markdown” I have been working to get a binding to github’s fork of cmark.
For the first part of this, I got some help in #native
writing a Perl module in the Alien:: namespace,
namely Alien::libcmark_gfm.
Armed with this module, I’ve been seeking to make CommonMark
work against the GitHub fork of libcmark.
So far things have been going well, and I decide to just be dumb. The API for libcmark-gfm is a bit different, so I’ll rename the packages from CommonMark to CommonMarkGFM.
Of course, this was the first problem: I was getting
errors about a package not existing, a package named CommonMarkGFM::N. What the hell does that mean? I haven’t changed much yet!
The problem was this bit of C code in the newly-renamed CommonMarkGFM.xs:
stash = gv_stashpvn("CommonMarkGFM::Node", 16, GV_ADD);
Okay, now I don’t know perlguts very well.
I don’t know what gv_stashpvn does (but I can find the docs for gv_stashpvn
and the name is a hint at what it does, in the terse nomenclature of Perl’s internal APIs)
The old string was 16 bytes long. Now it should be 19,
and that perfectly explains why I saw CommonMarkGFM::N.
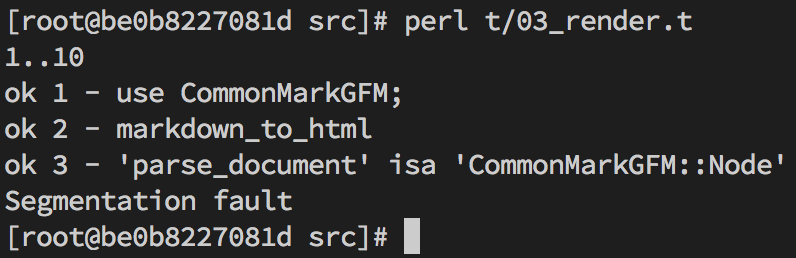
So I get past that. and now the test suite segfaults.
1..10 ok 1 - use CommonMarkGFM; ok 2 - markdown_to_html ok 3 - 'parse_document' isa 'CommonMarkGFM::Node' Segmentation fault
Hey, maybe this is the same as the first problem I fixed?
So I go looking for that problem, and I find it!
We have some lengths hard-coded in the typemap file
(no, aside from the fact it maps types, I don’t know what the typemap file does. I’m not usually hacking in perlapi).
T_NODE
$var = (cmark_node*)S_sv2c(aTHX_ $arg, \"CommonMarkGFM::Node\", 19, cv,
\"$var\");
/* more omitted */
So I fix those problems, but they were not my problem.
I’m still getting a segfault…
I’m really quite excited at this moment! I have a problem that I can apply things I learned about from this wonderful blog by Julia Evans.
I’ve already been using a Dockerfile to try to compile and test this code so I just need to install Valgrind (and maybe gdb too) and see what happens.
So I run valgrind:
==16== Access not within mapped region at address 0x88 ==16== at 0xEF4685C: cmark_render_html_with_mem (in /usr/local/lib64/perl5/auto/share/dist/Alien-libcmark_gfm/lib/libcmark-gfm.so.0.28.3.gfm.12) ==16== by 0xED0A11D: XS_CommonMarkGFM__Node_interface_render (CommonMarkGFM.c:898) ==16== by 0x4ED6814: Perl_pp_entersub (pp_hot.c:2888) ==16== by 0x4ED4B05: Perl_runops_standard (run.c:40) ==16== by 0x4E7D0D7: perl_run (perl.c:2435) ==16== by 0x400E73: main (perlmain.c:117)
Huh, interesting. Okay, maybe I can use gdb to set a breakpoint there.
(gdb) b cmark_render_html_with_mem Function "cmark_render_html_with_mem" not defined. Make breakpoint pending on future shared library load? (y or [n]) y Breakpoint 1 (cmark_render_html_with_mem) pending.
Our function doesn’t exist yet as it’s in a shared object that will get loaded later. This is fine — except it isn’t. My breakpoint never happens.
Huh! I guess (as it turns out, wrongly) that maybe I need to change my compilation options. And I also assume the segfaulting is because of something in the Perl extension code.
So maybe it’s that we compile with -02. My gcc is too old to support -Og, so let’s try -O0.
At this point, I’m just copying the line from make’s output and changing it. I just want to get some details in gdb damn it!
So I run the following:
perl Makefile.PL make gcc -c -I/usr/local/lib64/perl5/auto/share/dist/Alien-libcmark_gfm/include -D_REENTRANT -D_GNU_SOURCE -fno-strict-aliasing -pipe -fstack-protector -I/usr/local/include -D_LARGEFILE_SOURCE -D_FILE_OFFSET_BITS=64 -O0 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector --param=ssp-buffer-size=4 -m64 -mtune=generic -DVERSION=\"0.280301\" -DXS_VERSION=\"0.280301\" -fPIC "-I/usr/lib64/perl5/CORE" CommonMarkGFM.c make install
Now I can run perl t/03_render.t again, under gdb, and see if I can get more details.
1..10 ok 1 - use CommonMarkGFM; ok 2 - markdown_to_html ok 3 - 'parse_document' isa 'CommonMarkGFM::Node' ok 4 - parse_document works ok 5 - render_xml ok 6 - render_man ok 7 - render_latex ok 8 - render_commonmark ok 9 - render functions return encoded utf8 ok 10 - render functions expect decoded utf8
My attitude thus far is clear in the tweet that followed:
https://twitter.com/dylan_hardison/status/954919967887011840Now I proceed to have fun.
I spent the time trying to figure out what -O1 vs. -O0 did, and I wrote a script to repeatedly re-compile that one file
with different options. Along the way, I learned how to make gcc spit out what options it is compiling with (gcc -Q -v ...).
I had some false positives, and then I went to sleep.
After a period of sleep, figured out I wanted the list of flags as a difference between -O0 and -O1. I cleaned up my compile.pl script
and ran it.
The answer is: all of them are fine. -O0 and all the feature flags of -O1 result in no segfault either. Adding -O1 back brings back the segfault. After some more searching of the gcc docs, it is implied some optimizations are just directly tied to the O level.
My fun is now over, and I’ll do the more boring task of figuring out why my code is broken.
Staring at my from gdb’s output is this:
warning: Error disabling address space randomization: Operation not permitted
After a bit of searching, I find a fix for this to run the docker image
with --security-opt seccomp=unconfined.
And suddenly, breakpoints work.
and I can debug the root variable that is passed to cmark_render_html_with_mem… and nothing is wrong there.
Probably I need to re-compile libcmark-gfm with more debugging, I think. Suddenly, I realize that cmark_render_html_with_mem takes three arguments, and the Perl XS code is only passing it two.
How does this work? Well, it appears to cast a pointer to a function pointer, and call it. Calling a function pointer with fewer arguments than it is declared to with is undefined behavior, and I guess the rest of the behavior I observed was nasal demons.
(as an FYI, this argument difference is an API change between upstream libcmark and libcmark-gfm).
Finally, this third argument is a linked list of syntax extensions,
and it’s not clear yet how I will need to pass that back and forth between perl and C. This is also indicative that CommonMarkGFM will need to be a fork of CommonMark
Hello!
Do you enjoy creative writing?
Would you like to help Bugzilla?
Right now, only myself and dkl are allowed access to sanitized bugzilla (bmo) database dumps. The vagrant and docker dev environments come with very rudimentry data sets (one product, a handful of versions) and it means the experience of our many contributors is sub-optimal. Frequently they’re not able to effectively test their ideas.
With this in mind, I have set up landfill.bugzilla.ninja. This is running the mozillabteam/bmo:latest docker container on a VM that I own. It contains no data that isn’t in the git repo.
I want to give people accounts on this – literally anyone – and have them:
1) Create products, components, versions, milestones, flags, tracking flags, keywords, groups, and other misc. metadata
2) Invent a bunch of fake bugs and comments. The more the better.
After we have a sufficient number of these created, I will take the data, sanitize it, and publish the data for all to use.
To get started, DM me on twitter (@dylan_hardison), send me an email dylan [at] hardison.net or hop in irc: #bugzilla on irc.mozilla.org
P.S.
Thematically, we can pretend this is a bug tracker for a fictional operating system written in Brainf*ck, or perhaps the bug tracker for the fictionary “sword art online” anime.
Or perhaps you can throw some machine learning at this – I don’t care as long as I get a diverse dataset for testing.
Recently in the Bugzilla Project meeting, Gerv informed us that he would be resigning, and it was pretty clear that my lack of technical leadership was the cause. While I am sad to see Gerv go, it did make me realize I need to write more about the things I do.
As is evident in this post, all of the things I’ve accomplished have been related to the BMO codebase and not upstream Bugzilla – which is why upstream must be rebased on BMO.
See Bug 1427884 for one of the blockers to this.
In 2017, we made over a dozen a11y changes, and I’ve heard from a well-known developer that using BMO with a screen reader is far superior to other bugzillas. 🙂
BMO is quite happy to use carton to manage its perl dependencies, and Docker handle its system-level dependencies.
We’re quite close to being able to run on Kubernetes.
While the code is currently turned off in production, we also feature a very advanced query translator that allows the use of ElasticSearch to index all bugs and comments.
I sort of wanted to turn each of these into a separate blog post, but I never got time for that – and I’m even more excited about writing about future work. But rather than just let them hide away in bugs, I thought I’d at least list them and give a short summary.
My favorite communities optimize for fun. Frequently fun means being able to get things done. So in 2017 I did the following:
In the last year, we had almost 500 commits to the BMO repo,
from 20 different people. Some people were new, and some were returning contributors (such as Sebastin Santy).
Back when I started working on BMO
we couldn’t add new dependencies without having someone build an RPM. For no particularly good reason, this made it so in general we didn’t add new dependencies often.
However, about a year ago I started poking at carton and came up with a process to run carton in a docker container that mirrors production, and tar up the resulting local/ directory.
For the last 6 months or so we have been able to add dependencies whenever we want. We can also track changes to the
full dependency tree.
The code for this is on github as mozilla-bteam/carton-bundles and it is a little ugly, but packaging code is rarely elegant.

You must be logged in to post a comment.